用python写爬虫
如何用python写一个爬虫可以指定关键词,爬取包含该关键词内容的网页
东西/原料
- ThinkBook15
- Microsoft Windows10.0.19043.1083
- PyCharm2019.2.3
方式/步调
- 1
建立项目,设置项目存储位置
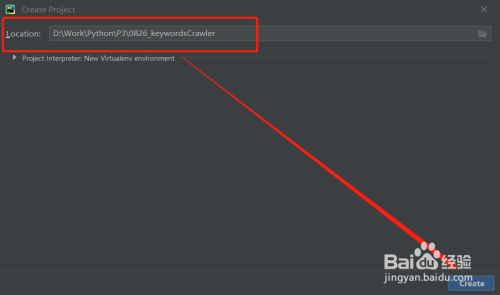
- 2
安装requests模块
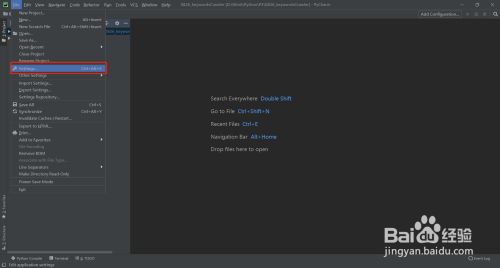
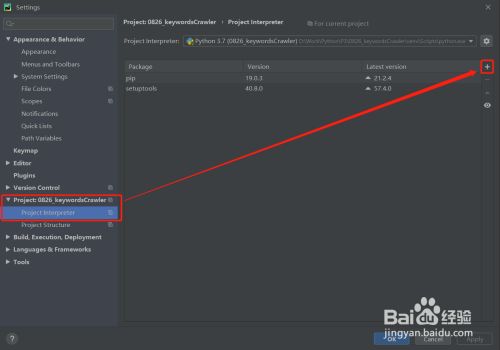
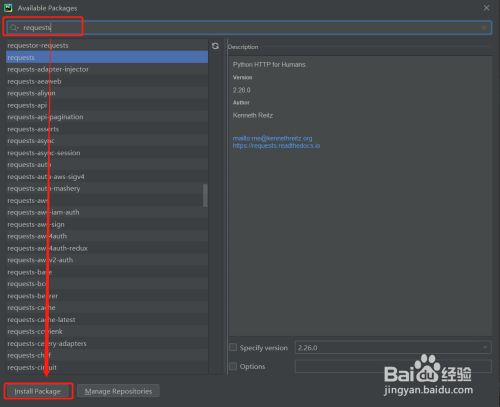
- 3
建立py文件

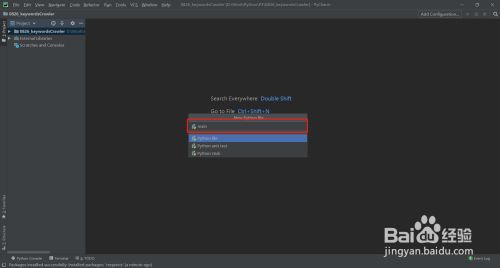
- 4
编写根本爬虫框架代码
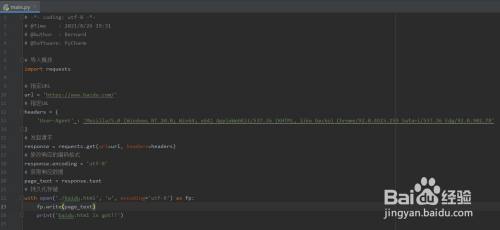
- 5
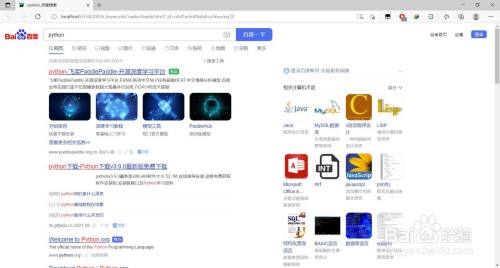
利用Microsoft Edge浏览器拜候百度,并进行关头词搜刮
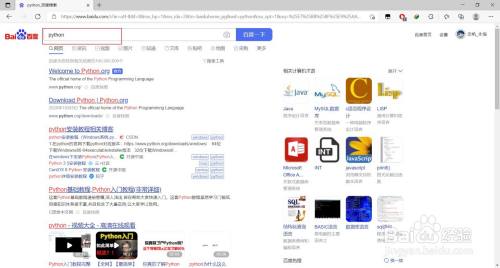
- 6
在搜刮到的页面中点击鼠标右键,在菜单中点击“查抄”打开浏览器自带的抓包东西
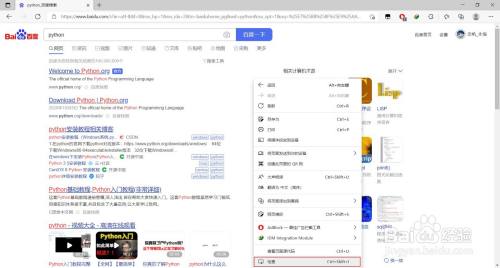
- 7
在抓包东西中选择“收集”标签选项
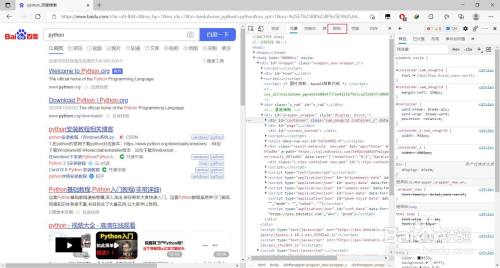
- 8
利用快捷键Ctrl+R进行刷新
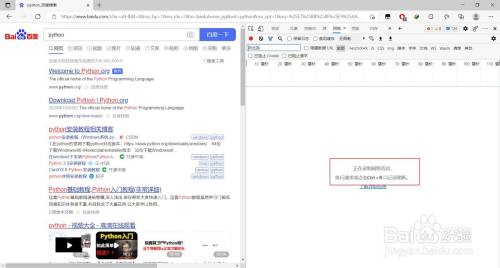
- 9
找到名称与请求域名不异的数据包
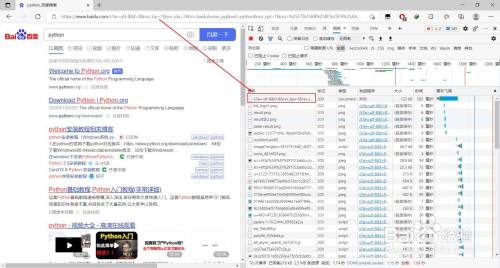
- 10
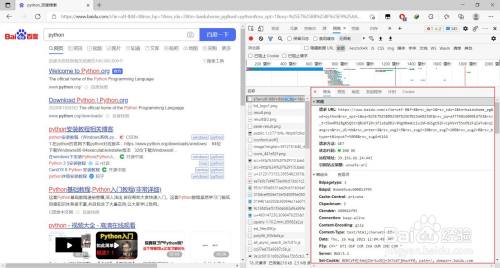
在数据包的“标头”标签选项详情中找到“查询字符串参数”,将此中的内容复制
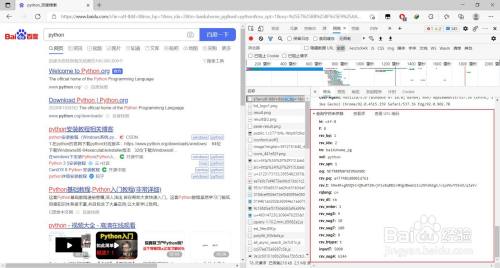
- 11
将复制的字符串参数在代码中封装当作字典,并在get()方式中传入params
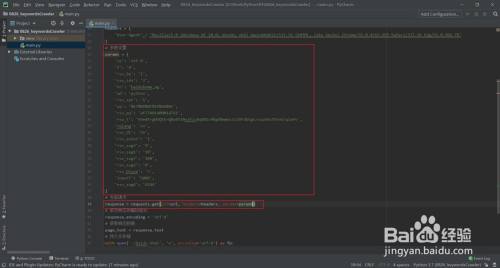
- 12
点窜指定的url
不雅察发现浏览器抓到的数据包中请求URL后半部门其实就是前面找到的那些字符串参数
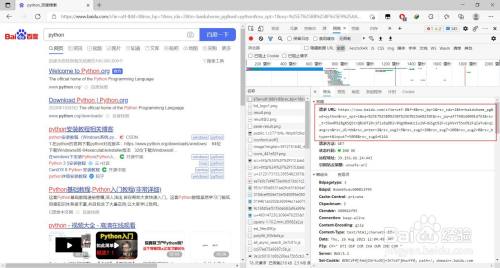

- 13
运行代码,代码当作功运行,生当作新文件
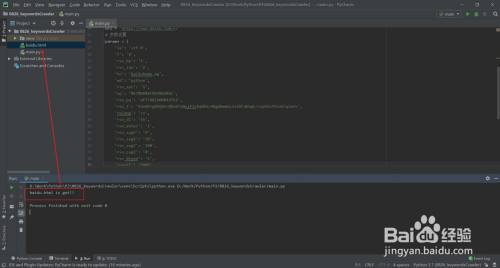
- 14
打开文件查看,和前面用浏览器搜刮到的页面一样,申明爬取当作功了
- 15
不雅察“字符串参数”中,wd后面的内容即为输入的关头词,是以在代码中将该参数动态化

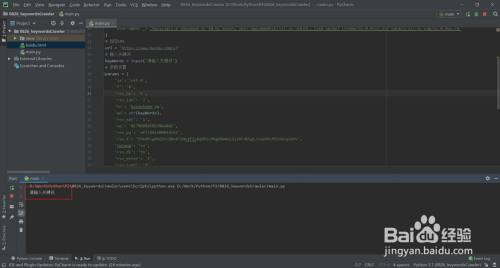
- 16
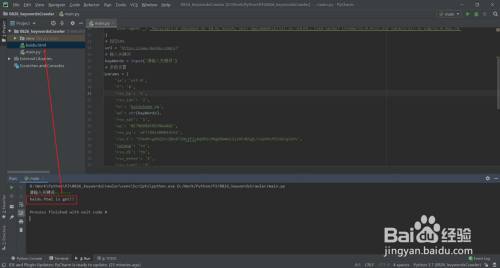
运行代码,键入关头词,运行完当作

- 17
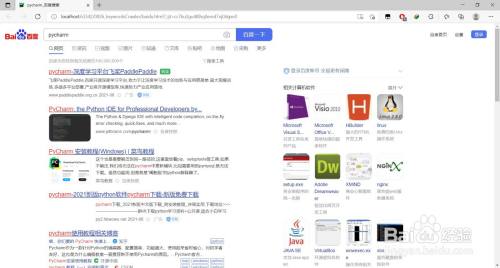
查看baidu.html文件,当作功爬取到所键入关头词相关的搜刮内容
 END
END
注重事项
- 分歧浏览器抓包东西界面各有分歧,需要按照具体浏览器矫捷操作
- 发表于 2021-08-28 13:01
- 阅读 ( 489 )
- 分类:电脑网络